The Baked in Bias of Chat GPT

Is Chat GPT biased? More than you might think. With authoritative sounding answers about just about anything, chat models like Chat GPT just might represent the future of where people get their information. But be careful what you believe.
Because of its programming, GPT is more than just an information portal. It is an opinion maker--an influencer.
Think about the effect of answers given by GPT. They sit upstream from public opinion. The answers found on GPT trickle down into common knowledge, separated from their origin.
That might not matter much if you are looking up a recipe for dinner. But if someone is searching a political or religious topic, it can make a very big difference. In these cases, the developers are secretly holding tremendous power to frame the issues in a way that moves public opinion. If the user is not aware of this, the power to influence is greater.
At Choose Digital Holiness, it is our hope to expose and uncover dangers BEFORE they have taken a firm grip on unsuspecting users. Therefore, we reveal these little known facts about how a chat model is trained.
In the press release version, Chat GPT was trained by crawling over billions of web sites, (including the full contents of Wikipedia) in order to amass the data set needed to answer questions on every topic. This process is what is known as the “unsupervised pre-training.”
What is not so well known is, that data set is pre-screened, by humans, to eliminate content that the trainers deem “offensive, biased, or harmful to society.” THAT, is a judgement call. What one person calls "harmful," another person might call painful truth.
In other words the training data is not without bias, it is a reflection of the biases of the trainers. Now, this could mean the elimination of profanity or hate speech. But it could also mean the elimination of anything that promotes religious or political positions that the trainers disagree with. If the answers coming from GPT are filtered, how do you know what is being filtered out?
The content removed from the data set used to train GPT is not publicly available. This is considered proprietary information. Why the secrecy—one might ask? Why not be transparent about it?
The second training step, after the “unsupervised pre-training,” is to fine-tune the model, based on pre-labeled categories. (by humans) What are those categories? This is very difficult to ascertain, for the data set is massive, and not all of it publicly available. But if, for example, certain content is placed in a category the trainers call “conspiracy theories” the chat model will reflect that opinion.
In being trained to answer questions, GPT might be trained on a dataset consisting of pairs of questions and answers, where the “correct answers” are labeled in advance. (by humans) The machine learns to answer similar questions based on what it has already been told is, “correct.” Does this sound like a sinister attempt to stack the deck? Well, that have not been the goal at all. Maybe, it was just an attempt to teach the machine to “think like a human.”
The problem is, it is impossible to think like a human, without also inheriting the biases of the human. To be biased, is precisely human. The question is: whose biases will prevail? Whose values are being baked in to the machine? These biases are being spread downstream to billions of users.
Even after a chat model is released and functioning, the trainers have the ability to intervene and steer its course. Training the machine or re-training it takes a lot of time. But if immediate intervention is deemed needed, algorithms and filters can be put into place to change an answer, in-between when it leaves the processor, and when it shows up on your screen. In other words, a human can enter the mix at any moment, and change the content of the answer.
GPT itself admits this:
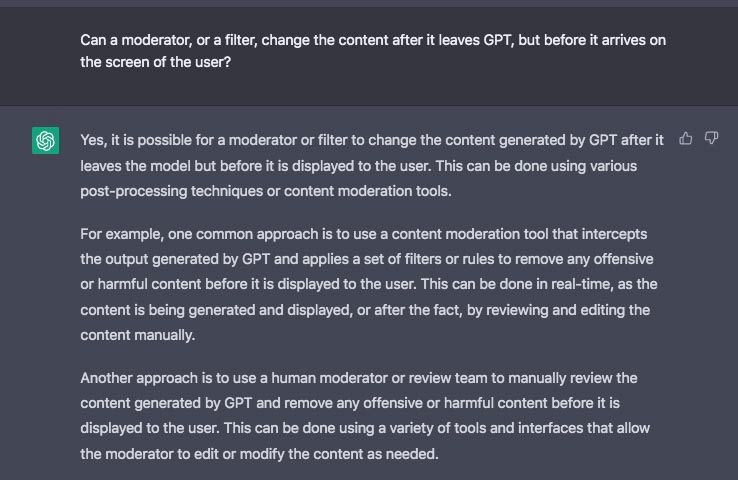
Once again, what is deemed "offensive or harmful" is completely a judgment call made by the human moderator.
One way to test for biases, is to ask GPT about some controversial political topic. If you are careful how you ask, suspicious things pop out. One such topic, by way of example, is global warming. We offer no opinion here on the truth or falsehood of the theory. But if GPT is asked to summarize the arguments AGAINST global warming, it cannot do it without slipping in ITS OWN CONCLUSION on the matter. It will say, after giving a few points,
"It's worth noting that the overwhelming majority of climate scientists agree that global warming is happening and that human activities are a major cause of it. While there may be some dissenting opinions, the evidence in favor of global warming is robust and well-established."
This is volunteered information. Whatever one might believe about global warming, that was not the question asked! The model was simply asked to list the arguments on one side of the question. It concludes by leaving the user with an authoritatively stated opinion—the “takeaway.” How did that takeaway get into the machine? Why does it feel the need to share it, when it was asked nothing of the sort?
Try this yourself on a few topics. Often, GPT will sandwich the information you asked for between a "conclusion" both before and after the information you asked for. So what is the takeaway you are left with? --the facts, or the volunteered conclusion? The unrequested editorializing becomes a very subtle opinion mover.
Without public access to the data set used to train GPT, we have no idea how many pre-programmed biases might be hiding behind its answers in thousands of topics. In many cases, these biases may be harmless. But if GPT is asked about some religious or doctrinal topic, will the machine have a pre-programmed bias that could pin a negative label on a peaceful religious group?
If at some future time, certain religious groups are labeled “hateful,” will all the answers GPT gives about that group volunteer that point? If so, the unaware public, which has no other information about that group, will be prodded down-stream in the direction the machine sent them.
Language based Chat models can quickly provide answers on a host of topics. No doubt that has many helpful uses. But as long as humans are allowed to intervene in those answers, these models also have a dangerous potential.
Conversational Chats could become the most powerful propaganda machines ever created.